



场景结构是城市增强现实(augmented reality,AR)进行信息标注、深度感知和遮挡处理的重要依据。在城市环境中,街道纵横,建筑物稠密,场景结构复杂[1],AR将提示信息叠加在建筑物表面能有效地辅助用户理解周围环境。现阶段城市AR研究[2-4]通常将文字、图形、模型等信息以层叠的方式“堆积”在屏幕上,提示信息与目标建筑物仅在位置上模糊对应,已逐渐难以满足人们的环境感知需求。其重要原因在于场景结构缺失[5]导致图形符号与场景图像在视觉效果上的“割裂”,特别是在复杂的建筑物场景中,即使地理配准[6]精度高,也存在信息指示不明确,用户理解困难等问题(图 1(a))。近年来,城市AR研究领域已有部分学者[5, 7-9]致力于在AR信息的表现样式中融入场景结构信息,如建筑物的轮廓、朝向和深度等,强化提示信息与目标对象之间的联系,使信息表达更为“有序”(图 1(b))。这种与场景结构高度契合的信息表现形式,在信息增强的同时尽可能地避免干扰视野,更符合人们对环境感知的视觉特点。

|
| 图 1 城市AR信息表达示例 Fig. 1 Examples of information representation in urban AR |
支持上述AR信息表达的关键在于快速准确地获取精细的场景结构信息,即场景图像中地理实体的轮廓、朝向、深度、分布和语义信息等。目前可用于城市户外AR信息表达的场景结构提取的方法主要有4类。第1类是基于预先构建的精细三维模型的方法[10],本质是将逼真的虚拟环境完全替代现实世界,但精细的三维模型获取困难,这类方法通常仅限于可控的试验环境。尽管文献[9]利用OpenStreetMap提供的公开2D地图数据构建城市三维模型,并应用于AR地理信息可视化,但这种简略的三维模型仅能描述简要的场景结构,而且建筑物的高程信息往往并不准确。第2类是基于即时定位与地图构建(simultaneous localization and mapping, SLAM)的方法[11-12],能适应场景的动态变化并构建场景的点云模型。如HoloLens探测并生成场景表面的Mesh格网,从中推断出简单的平面图形和语义信息。但城市AR通常并不会预先扫描整个环境,而且这类方法目前仅支持简单的场景结构推理,如室内天花板、地面、墙面等基本语义,不区分地理实体。第3类是基于人工提取的方法,利用人的经验知识预先从地图或场景模型中挑选出适宜标注的信息依附平面[5]。如文献[13]借助俯视图,考虑视角、遮挡和用户感受等因素,交互式地在AR平视图中标注地物。但该方法操作烦琐、专业性强,仅适用于AR中少量的提示信息的动态配置。第4类是基于图像处理的方法,根据场景图像中的结构线索,如灭点、阴影等,推断出场景结构[14-16]。这类方法在特定场景下能提取出少量建筑物的朝向或高度等信息,但并不明确其所属的建筑物。文献[8]基于深度学习的方法构建了PlaneNet网络,能从单张RGB图像中提取各平面的轮廓、朝向和深度。该方法提取的轮廓反映的是场景中平面的几何结构,并不区分地理实体,因此仍需要人工地指定AR信息呈现的区域。
2D地图作为城市AR重要的数据源,描述了地理实体的位置轮廓和空间布局,为场景结构的提取提供了先验信息。文献[17]将2D地图中地理要素在场景图像上的投影结果,作为交互式图像分割[18-19]中的前后景的标记,进行场景图像分割,用于场景深度图的构建。受该方法的启发,本文借助目前广泛易得的2D地图,实现对建筑物场景结构的自动化提取。事实上,场景图像是客观世界在2D平面上的投影,也遵循客观世界在构成上的一般规律[20]。根据这些规律,在地理配准技术的支持下,笔者结合2D地图中建筑物的轮廓信息对场景图像进行语义分割,建立图像区域与地理要素之间的映射关系,进而实现建筑物场景结构的自动化提取。与计算机领域中常规的语义分割[21-22]不同,本文对场景图像中的建筑物及其立面进行分割。这种与地图中地理要素相对应的语义分割和结构提取方法,将支持更精细的融合场景结构的AR信息表达。
1 建筑物场景结构提取方法人在理解场景图像时,通常根据先验知识从图像中寻找重要的结构线索,对场景进行解析和重构。本文提出的建筑物场景结构提取算法的关键是根据2D地图和场景图像拍摄时的位姿信息对场景图像进行语义分割。如图 2所示,算法的数据输入均是城市AR中常用的数据,其中概略的2D地图及其属性信息很容易从公开的地图数据源(如OpenStreetMap)中广泛获取。算法分为3个环节:①场景结构线索提取,根据2D地图中建筑物轮廓和属性信息构建建筑物场景的概略模型,然后利用场景图像的位姿信息和透视关系计算地理要素投影到场景图像上的区域,并从中提取场景结构的图形线索和视觉线索;②场景图像语义分割,根据建筑物场景构成的一般规律将场景图像区域划分为“天空”“地面”“竖直物体”3类,并结合场景结构的图形线索和视觉线索,对场景图像进行语义分割,建立地理要素与场景图像之间的映射关系;③场景结构提取与生成,根据概略模型中地理要素的构成,对三维场景进行重构,提取出场景图像中建筑物立面的区域轮廓、场景深度、平面朝向等结构信息。

|
| 图 2 建筑物场景结构提取算法流程 Fig. 2 Flow chart of building scene structure extraction algorithm |
1.1 场景结构线索提取
地理要素在2D地图中通常以简要的位置和轮廓的形式存在,作为AR信息表达的重要数据源[23]。地理要素投影到场景图像上的结果,在图形特征和视觉特征上为语义分割提供了的线索。本文根据建筑物场景的一般构成规律,从地图和场景图像中提取场景结构线索,辅助场景图像语义分割。
(1) 建筑物场景结构分类。经过透视投影后,场景图像因维度下降导致场景结构丢失。根据单张图像恢复场景结构,从原理上讲,会产生无穷多个可能。但人眼却仅凭场景图像就能在脑海中构建场景的三维结构。这是因为建筑物场景在构成上遵循一定的规律,如天空在建筑物的上方,同一地物在场景空间中是连续的。人在理解场景图像时,正是在掌握了几何投影的知识基础上,按照这些先验知识进行理解的。文献[24]根据平视条件下物体平面的朝向,将户外场景的三维结构划分为“天空”“地面”和“竖直物体”3类,其中“地面”是指马路、草坪等平行于地平面的物体;“竖直物体”主要指建筑物、树木等垂直于地面的地物。反映到场景图像中,“地面”在“竖直物体”下侧,“天空”在“竖直物体”上方。本文采用相同方式对建筑物场景结构进行分类(图 3(c)),其中蓝色代表“天空”,橙色代表“地面”,黄色代表“竖直物体”。

|
| 图 3 建筑物场景图像结构线索描述 Fig. 3 Description of building scene image structure clues |
(2) 地理要素形状线索。地图是客观世界抽象和概括后的结果[25],描述了场景结构更为本质的特征,如地物的位置、形状、方向和属性等信息(图 3(b))。根据这些信息能概略地重构场景三维结构,如Kendzi3D(https://wiki.openstreetmap.org/wiki/JOSM/Plugins/Kendzi3D)基于OpenStreet Map中2D地图数据对城市环境进行重构和可视化。城市AR中,通常选择性地将地理信息配准到场景图像上[26],这种俯视视角与AR中平视视角在视野范围、空间布局、语义关联等空间感知方面形成互补。本文基于该想法,利用2D地图中关于建筑物的描述,构建建筑物场景的简要模型,并转换成场景图像语义分割的形状线索。与Kendzi3D可视化不同,本文更侧重于建筑物在场景图像中的形状和位置的估计。
以图 3(b)城市2D地图中建筑物轮廓ab段为例,在进行建模时,该轮廓对应三维空间中的建筑物的竖直立面,其高度根据建筑物的楼层数估算[27]。在已知场景图像拍摄时视点P的位姿信息和视景体参数的条件下,可计算出该立面对应的图像区域(图 3(d)中F1),作为语义分割中建筑物轮廓ab对应的种子区域。同理,建筑物上方一定距离的种子区域S1为天空,而下方一定距离的种子区域G1为地面。在实际解析过程中,因位姿信息存在一定误差,生成的种子区域可能会超出地理实体对应的图像区域,导致分割失败。因此,在生成种子区域后,会按比例适当缩小种子区域的几何形状。
(3) 场景图像视觉线索。场景图像中地理要素的形状并不规则,仅根据形状线索不足以进行有效的分割。而人眼在区分地物时,通常依据的是地物的颜色和纹理等视觉特征。基于该原理,根据种子区域与周围区域的视觉相似度,能对周围区域对应的地理要素进行归类,完成场景图像的分割。场景图像是以像素矩阵的形式存在,逐像素地进行归类不仅计算量大,而且容易受到图像噪声的干扰。因此,在进行图像分割时,常采用超像素的方式进行过分割处理[19, 28]。超像素是由具有相似纹理、颜色、亮度等特征的相邻像素构成的不规则像素块,具有一定的视觉意义。在试验过程中,文献[17]采用的Graph-Based方法分割的结果在形状上非常不规则,在相邻建筑物颜色相近时,容易产生错误分割。SLIC方法[29]能很好地平衡几何形状和颜色特征(图 3(e)),经GPU加速后能达到250FPS(https://arxiv.org/abs/1509.04232),满足图像分割的实时性要求。在过分割的基础上,从种子区域开始,根据超像素之间的视觉相似性进行生长合并,形成最终的聚类结果。超像素一般在颜色、纹理上表现一定的差异。本文采用颜色直方图衡量超像素Si与Sj之间的视觉相似度
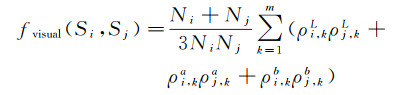 (1)
(1)
式中,N表示超像素的面积;m为单通道颜色直方图的区间数量;ρi, kL为超像素Si在L颜色通道上k区间的分布频率。fvisual(Si, Sj)越大,表示Si与Sj属于同一地物的可能性越高。
(4) 场景图像距离线索。地理实体在地理空间中通常是紧凑、连续的,场景图像中地理要素对应的图像区域一般情况下也是紧凑、连续的。超像素到种子区域的几何距离越近,属于同一类地物的可能性越高。在建筑物场景建模过程中,因高度缺失或定位误差,竖直方向精度往往不如水平方向。例如根据楼层数估算建筑物高度,相较于位置和轮廓,精度并不高。表现在场景图像上,到种子区域相同几何距离的情况下,图像区域在水平方向归属于该种子区域的可能性比竖直方向更高。据此,本文定义超像素Si到种子区域Rj的归一化后的距离相似度
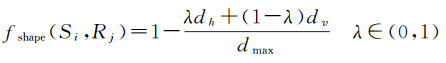 (2)
(2)
式中,dh为Si到Rj的水平距离;dv为Si到Rj的竖直距离;dmax表示最大距离;λ为水平距离和竖直距离之间的权重,与地物高度估算的精度有关。fshape(Si, Rj)越大,表示Si属于Rj的可能性越高。如图 3(f)所示,ABCD为图 3(d)中轮廓bc生成的种子区域,dh为超像素质心P到直线BC的像素距离,dv为P到直线AB的像素距离。当P在种子区域内部时,dh和dv均为0。
1.2 场景图像语义分割基于上述场景结构线索,可将建筑物场景图像分割成与地图中地理要素对应的多个图像区域。将场景图像进行超像素分割,形成内部视觉特征一致的超像素,超像素内部均属于同一地理实体。采用超像素邻接图表示场景图像,相比于像素矩阵,具有更好的区域视觉特征,同时降低了分割算法的复杂度。
场景图像中,“天空”和“地面”通常具有一致的颜色或纹理。根据2D地图中地理要素构建的图形线索,生成种子区域,作为分水岭图像分割算法[30]的输入,对场景图像按场景结构分类进行语义分割。针对任意超像素P,其质心所在的像素对应的语义标识即为P所属的结构分类,如图 4所示。

|
| 图 4 基于超像素的场景图像结构分类 Fig. 4 Classification process of scene image structure based on superpixel |
进一步对“竖直物体”按建筑物立面进行分割,根据建筑物轮廓生成的图形线索,可获得建筑物立面对应的种子区域。首先将种子区域内部的超像素标记为对应的建筑物立面;然后基于邻接图生长算法,针对剩余的超像素进行区域合并,如图 5所示。在区域生长合并过程中,采用贪心策略,将种子区域相邻超像素作为候选集,从中寻找到相似度最高的超像素P,进行合并。定义相似度函数为
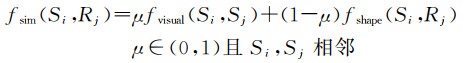 (3)
(3)

|
| 图 5 超像素邻接图区域生长算法 Fig. 5 Schematic diagram of region growth algorithm based on adjacency graph for superpixel |
式中,μ为视觉距离与几何距离在相似度计算时所占的权重,与相邻地理要素之间的纹理、颜色等视觉相似度有关。图 5中Rj为种子F1—F5区域,Si为候选集中的超像素P,Sj为生长区域中与Si相邻的超像素。
对图像中所有的超像素进行归类合并,最终获得场景图像语义分割的结果(图 6)。分割结果存储的是场景图像中逐个像素所属的语义标识。经过语义分割,场景图像被分割成天空、地面和多个建筑物立面,其中每个立面对应2D地图中建筑物的一条轮廓边。这种与地理实体直接关联的语义信息更全面地描述了场景图像的含义,这在城市AR自适应信息表达中十分必要。

|
| 图 6 建筑物场景图像语义分割结果 Fig. 6 Semantic segmentation results of building scene image |
1.3 场景结构提取与生成
经过场景图像语义分割后,建立起图像区域与地理要素之间的映射关系。这种按像素描述的语义信息,经提取能生成便于城市AR信息处理的区域轮廓、场景深度和平面朝向等场景结构信息。
(1) 区域轮廓。针对语义分割的结果,从种子区域出发,按逆时针或顺时针方向寻找区域边界,可提取场景的中每个平面对应的轮廓(图 7(a))。区域轮廓的位置、面积和形状等特征可作为AR符号位置、尺寸、数量等样式的重要约束。

|
| 图 7 建筑物场景结构提取效果 Fig. 7 Results of building scene structure extraction |
(2) 场景深度。场景图像中每个像素对应三维空间中一条以视点为起点的射线。计算每条射线与对应平面相交形成的线段的距离,作为该像素的场景深度,最终可获得场景图像对应的深度图(图 7(b))。场景深度是AR进行遮挡处理的重要依据。
(3) 平面朝向。根据2D地图中的地理要素的几何信息和用户的位姿信息,可计算出3D场景中地理要素的立面在用户视角下的法向量(图 7(c))。平面朝向是AR符号的朝向和分布的重要参考。
2 试验与分析 2.1 试验数据利用文献[31]提供的格拉茨地区公开数据集进行试验。该数据集包含32个市区和城郊的建筑物场景(图 8(a)),包括Apple iPad Air采集的场景图像和传感器的位姿数据。从OpenStreetMap数据中截取对应场景的大比例尺地图数据,并根据场景图像与3D模型之间的对应关系,求解出场景图像拍摄时的摄像机的位姿作为位姿真值(图 8(b))。因为传感器采集的位姿数据误差较大,直接影响场景结构提取的效果,为减少地理配准误差的干扰,试验中涉及的位姿数据均使用数据集提供的位姿真值。

|
| 图 8 典型建筑物场景结构提取效果 Fig. 8 Results of structure extraction for typical building scenes |
另外,为了检验语义分割的精度,本文处理时采用人工方式对场景图像进行了语义标注(图 8(c))。语义标注过程中,根据该地区的2D地图、三维模型和街景图像,标注出场景图像中每个建筑物的立面轮廓,忽略部分遮挡物(如汽车、树木等)。
2.2 试验对比使用本文方法对数据集中全部的建筑物场景进行了结构提取,图 8展示了其中部分具有代表性的场景的提取效果。为进一步检验该方法的有效性,下面对算法的精度和效率进行量化评估。
2.2.1 建筑物场景图像语义分割质量场景结构提取的精度与多种因素有关,如地图数据精度、地理配准精度、场景图像质量等,难以直接衡量。而语义分割是进行场景结构提取的关键环节,其分割质量直接影响结构提取的效果,因此试验重点对语义分割的质量进行评估。目前城市AR中场景图像分割面临巨大挑战,建筑物立面粒度的图像分割十分困难。文献[17]提出的分割方法(Graz),根据建筑物要素信息自动地分割要素所对应的图像区域,并应用于城市AR信息标注和遮挡处理等,相较于其他需要人为判定的方法,在图像分割的精度和粒度的上更适合精细的城市AR信息表达。因此本文以文献[17]提供的思路实现的逐要素分割方法(Graz)为对照,在超像素数量为500、1000、1500、2000等4种条件下,利用本文方法对数据集中建筑物场景图像进行语义分割,分割结果与人工语义标注的结果(图 8(c))进行对比,计算平均分割精准度(图 9(a))、轮廓形变量(图 9(b))和轮廓位置偏移量(图 9(c))。

|
| 图 9 试验效果评估 Fig. 9 Evaluation results of the extraction method |
语义分割的精准度采用平均准确率(MPA)、平均召回率(MPR)和平均交并比(MIoU)来度量。根据统计结果(图 9(a)),在不同超像素数量条件下,本文方法在该数据集上的表现都明显优于对照方法,MPA和MPR都保持在90%左右,MIoU保持在80%以上。本文方法的精准度受超像素数量变化影响较小,在数量达到1000时,分割精准度趋于稳定;对照方法随着超像素数量的增多,分割精准度明显提升。
轮廓形变也是衡量分割质量的重要指标,通常采用轮廓间的Hausdorff距离度量,距离越大,形变越严重。根据统计结果(图 9(b)),本文方法在保持原有轮廓方面,显著优于对照方法;超像素数量越多,本文方法和对照方法中形变量明显降低。
轮廓的位置偏移描述了分割结果相对标注结果的整体偏移,通常采用轮廓间像素的平均垂距衡量,垂距越大,偏移越严重。根据统计结果(图 9(c)),本文方法中,建筑物立面分割的轮廓的位置偏移明显优于对照方法。随着超像素数量的增加,本文方法的位置偏移略有下降,而对照方法则显著降低。
2.2.2 建筑物场景结构提取效率试验平台选用的是微星VR One 6RE-012CN,配置为4核CPU,主频2.7 GB,内存16 GB,GTX1070显卡。试验原型系统是利用VS2017基于OpenCV、OpenGraphScene等开源库实现。场景图像按640×360的分辨率处理,超像素数量设置为1000。系统运行稳定后,统计场景结构提取的各阶段的平均耗时(图 10(d)),包括超像素分割(SP分割)、结构分类、超像素合并(SP合并)、场景结构提取。其中SP分割阶段采用了GPU加速,耗时稳定在12 ms左右;场景结构提取阶段包括图像区域轮廓跟踪和平面朝向计算(轮廓和朝向),以及场景深度计算(场景深度),其中逐像素的深度计算比较耗时(80%以上)。单帧场景图像结构提取的平均运行时间为30~40 ms,基本满足实时性要求。在常规的城市AR应用中,不需要逐像素的深度信息,如果仅提取区域轮廓和平面朝向信息,处理单帧场景图像仅需25 ms左右。

|
| 图 10 不同方法的场景图像语义分割结果 Fig. 10 Results of different approaches for scene image semantic segmentation |
2.3 结果讨论
从试验效果来看,利用2D地图中概略的属性和轮廓等先验信息,能对建筑物场景图像进行结构解析,实时有效地提取出建筑物立面对应的区域轮廓、平面朝向和场景深度。相比于对照方法,本文方法在语义分割的精度、轮廓形变误差和位置轮廓偏移方面都明显优于对照方法。可能的原因是,一方面在场景图像过分割处理时,本文采用SLIC方法[29]能很好地平衡几何形状和纹理特征,而对照方法采用的Graph-based方法[28]更侧重于纹理特征,超像素的轮廓难以区分纹理相似的建筑物立面。另一方面,本文方法将建筑物立面和天空、地面分离,然后根据地图中建筑物的轮廓同时进行多立面分割,保持场景结构的整体性;对照方法逐要素地分割场景图像,缺乏建筑物立面之间的约束,导致分割结果中轮廓区域相互重叠,精度和效率均受到影响。
与计算机视觉领域中的语义分割方法[21-22]不同,本文方法的分割结果与地图中的地理要素对应,描述了场景图像更详细的语义信息。前者是将样本数据中学习的图像语义特征作为先验信息,但建筑物在样本标注时通常被当作Stuff类,并不区分个体,在分割结果中建筑物是混合在一起的(图 10(a))。而本文方法的先验信息来自大比例尺地图,其中描述了建筑物的主要轮廓和属性,经语义分割处理后,能将场景图像中的建筑物分割成单个立面的形式(图 10(b)),支持更精细的AR信息表达。
试验中也发现,语义分割的精度对场景结构提取的效果影响较大。在图像区域纹理高度相似的情况下,超像素并不能严格地表示建筑物立面的边缘,导致提取的区域轮廓在边缘处呈锯齿状(图 11(a))。对距离远的目标进行分割时,因配准误差和视觉纹理模糊的影响,分割误差较大,导致场景深度图出现“孔洞”(图 11(b))。另外,如果场景图像中存在大范围的遮挡物而地图中缺乏相关的描述,如距离近的电线杆、广告牌等,会导致分割结果误差较大(图 11(c))。

|
| 图 11 存在的问题 Fig. 11 Existing problems |
本文方法的先验信息主要来自概略的2D地图,缺乏场景中移动的物体(如汽车、行人等)和被概括的物体(如广告牌、电线杆等)的相关描述,而这些物体可能会成为平视状态下主要的遮挡物。试验发现这些“遮挡物”会对场景结构提取的结果产生一定的干扰,因此本文方法目前更适合静态的、轮廓显著的地理实体(如建筑物)的场景结构提取。
3 结束语针对目前城市AR中场景结构提取难、效率低的问题,本文提出一种基于2D地图先验知识从场景图像中自动化地提取建筑物场景结构的方法。该方法在地理配准的基础上,将2D地图中建筑物的轮廓和属性信息转化为图形线索和视觉线索,引导场景图像语义分割,建立场景图像与2D地图地理要素之间的映射,并最终生成区域轮廓、平面朝向和场景深度等场景结构信息,对城市AR融合场景结构进行自适应信息表达具有重要意义。试验表明,本文方法针对建筑物场景能够实时有效地提取结构信息,而且建筑物立面轮廓的精准度、形变误差和位置偏移误差均明显优于对比方法。但本文的测试场景具有一定的局限性,数据集涵盖的场景大多数是近距离相对简单的建筑物场景,在距离远、纹理相似或存在大面积遮挡物的场景中,可能会出现锯齿边缘、分类错误或孔洞效应等现象,这是后续改进的主要工作之一。另外,本文方法目前更适合静态的、轮廓显著的地理实体(如建筑物)的场景结构提取,结合计算机视觉领域的语义分割和目标识别的方法,为场景图像解析提供更实时准确的语义信息,实现更广泛的地理实体的场景结构自动化提取,是后续需要进一步研究的内容。
| [1] |
YOU Xiong, ZHANG Weiwei, MA Meng, et al. Survey on urban warfare augmented reality[J]. ISPRS International Journal of Geo-Information, 2018, 7(2): 46. |
| [2] |
LEHIKOINEN J, SUOMELA R. WalkMap:Developing an augmented reality map application for wearable computers[J]. Virtual Reality, 2002, 6(1): 33-44. |
| [3] |
曲毅, 李爱光, 徐旺, 等. 基于位姿传感器的户外ARGIS注册技术[J]. 测绘科学技术学报, 2017, 34(1): 106-110. QU Yi, LI Aiguang, XU Wang, et al. Outdoor ARGIS registration techniques based on position-posture sensor[J]. Journal of Geomatics Science and Technology, 2017, 34(1): 106-110. |
| [4] |
MEAWAD F. InterAKT: a mobile augmented reality browser for GEO-social mashups[C]//Proceedings of the 4th International Conference on User Science and Engineering (i-USEr). Melaka, Malaysia: IEEE, 2016: 167-171.
|
| [5] |
葛林, 庄晓斌, 华炜, 等. 面向城市增强现实的高融合度信息标注方法[J]. 系统仿真学报, 2014, 26(9): 2015-2022. GE Lin, ZHUANG Xiaobin, HUA Wei, et al. High fusion information annotation method for city augmented reality[J]. Journal of System Simulation, 2014, 26(9): 2015-2022. |
| [6] |
邓晨, 游雄, 张威巍, 等. 基于2D地图的城市户外ARGIS视觉辅助地理配准技术[J]. 测绘学报, 2019, 48(10): 1305-1319. DENG Chen, YOU Xiong, ZHANG Weiwei, et al. A vision-aided GEO-registration method for outdoor ARGIS in urban environments based on 2D maps[J]. Acta Geodaetica et Cartographica Sinica, 2019, 48(10): 1305-1319. DOI:10.11947/j.AGCS.2019.20190007 |
| [7] |
KASAPAKIS V, GAVALAS D. Occlusion handling in outdoors augmented reality games[J]. Multimedia Tools and Applications, 2017, 76(7): 9829-9854. |
| [8] |
LIU Chen, YANG Jimei, CEYLAN D, et al. PlaneNet: piece-wise planar reconstruction from a single RGB image[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 2579-2588.
|
| [9] |
ZOLLMANN S, POGLITSCH C, VENTURA J. VISGIS: Dynamic situated visualization for geographic information systems[C]//Proceedings of 2016 International Conference on Image and Vision Computing New Zealand. Palmerston North, New Zealand: IEEE, 2016: 2151-2205.
|
| [10] |
BELL B, FEINER S, HÖLLERER T. View management for virtual and augmented reality[C]//Proceedings of the 14th Annual ACM Symposium on User Interface Software and Technology. New York: ACM, 2001: 101-110.
|
| [11] |
LI Peiliang, QIN Tong, HU Botao, et al. Monocular visual-inertial state estimation for mobile augmented reality[C]//Proceedings of 2017 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). Nantes, France: IEEE, 2017: 11-21.
|
| [12] |
LIU Haomin, ZHANG Guofeng, BAO Hujun. Robust keyframe-based monocular SLAM for augmented reality[C]//Proceedings of the 2016 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). Merida, Mexico: IEEE, 2017: 1-10.
|
| [13] |
WITHER J, DIVERDI S, HOLLERER T. Using aerial photographs for improved mobile AR annotation[C]//Proceedings of the 2006 IEEE/ACM International Symposium on Mixed and Augmented Reality. Santa Barbara, CA, USA: IEEE, 2006: 159-162.
|
| [14] |
GUPTA A, EFROS A A, HEBERT M. Blocks world revisited: image understanding using qualitative geometry and mechanics[C]//Proceedings of the 11th European Conference on Computer Vision. Berlin: Springer, 2010: 482-496.
|
| [15] |
SAXENA A, SCHULTE J, ANDREW Y N. Depth estimation using monocular and stereo cues[C]//Proceedings of the 20th International Joint Conference on Artificial Intelligence. Hyderabad, India: ACM, 2007: 2097-2203.
|
| [16] |
王思洁, 方莉娜, 陈崇成, 等. 基于结构化场景的单幅图像建筑物三维重建[J]. 地球信息科学学报, 2016, 18(8): 1022-1029. WANG Sijie, FANG Lina, CHEN Chongcheng, et al. A single view type 3D reconstructive method for architecture based on structured scene[J]. Journal of Geo-information Science, 2016, 18(8): 1022-1029. |
| [17] |
ZOLLMANN S, REITMAYR G. Dense depth maps from sparse models and image coherence for augmented reality[C]//Proceedings of the 18th ACM Symposium on Virtual Reality Software and Technology. New York, NY, United States: ACM, 2012: 53-60.
|
| [18] |
SANTNER J, POCK T, BISCHOF H. Interactive multi-label segmentation[C]//Proceedings of the 10th Asian Conference on Computer Vision (ACCV). Berlin: Springer, 2011: 397-410.
|
| [19] |
KHATTAB D, EBIED H M, HUSSEIN A S, et al. Multi-label automatic GrabCut for image segmentation[C]//Proceedings of the 14th International Conference on Hybrid Intelligent Systems. Kuwait, Kuwait: IEEE, 2014: 152-157.
|
| [20] |
武晖, 于昕, 隋尧, 等. 融合上下文信息的场景结构恢复[J]. 中国图象图形学报, 2012, 17(7): 839-845. WU Hui, YU Xin, SUI Yao, et al. Structure recovery algorithm using contextual information[J]. Journal of Image and Graphics, 2012, 17(7): 839-845. |
| [21] |
CHEN Bike, GONG Chen, YANG Jian. Importance-aware semantic segmentation for autonomous vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(1): 137-148. |
| [22] |
KIRILLOV A, HE Kaiming, GIRSHICK R, et al. Panoptic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2019. Long Beach, CA, USA: IEEE, 2019: 9404-9413.
|
| [23] |
孙敏, 陈秀万, 张飞舟, 等. 增强现实地理信息系统[J]. 北京大学学报(自然科学版), 2004, 40(6): 906-913. SUN Min, CHEN Xiuwan, ZHANG Feizhou, et al. Augment reality geographical information system[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2004, 40(6): 906-913. |
| [24] |
HOIEM D, EFROS A A, HEBERT M. Automatic photo pop-up[J]. ACM Transactions on Graphics, 2005, 24(3): 577-584. |
| [25] |
高俊. 地图学四面体——数字化时代地图学的诠释[J]. 测绘学报, 2004, 33(1): 6-11. GAO Jun. Cartographic tetrahedron:explanation of cartography in the digital era[J]. Acta Geodaetica et Cartographica Sinica, 2004, 33(1): 6-11. |
| [26] |
SCHALL G, JUNGHANNS S, SCHMALSTIEG D. The transcoding pipeline: automatic generation of 3D models from geospatial data sources[C]//Proceedings of the 1st International Workshop on Trends in Pervasive and Ubiquitous Geotechnology and Geoinformation. Park City, Utah: Springer, 2008: 1-6.
|
| [27] |
KASPERI J, EDWARDSSON M P, ROMERO M. Occlusion in outdoor augmented reality using geospatial building data[C]//Proceedings of the 23rd ACM Symposium on Virtual Reality Software and Technology. New York, NY, United States: ACM, 2017: 1-15.
|
| [28] |
FELZENSZWALB P F, HUTTENLOCHER D P. Efficient graph-based image segmentation[J]. International Journal of Computer Vision, 2004, 59(2): 167-181. |
| [29] |
ACHANTA R, SHAJI A, SMITH K, et al. SLIC superpixels compared to state-of-the-art superpixel methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274-2282. |
| [30] |
VINCENT L, SOILLE P. Watersheds in digital spaces:an efficient algorithm based on immersion simulations[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1991, 13(6): 583-598. |
| [31] |
ARTH C, PIRCHHEIM C, VENTURA J, et al. Instant outdoor localization and SLAM initialization from 2.5D maps[J]. IEEE Transactions on Visualization and Computer Graphics, 2015, 21(11): 1309-1318. |